Dernière mise à jour : 07/09/2024 à 08h59
Table des matières
Introduction
Il est tout a fait possible d'utiliser directement sur votre PC des modèles d'IA générative Open Source. Ces modèles "LLM" ne sont pas aussi développés que ceux proposés par OpenAI, ou Anthropic. Toutefois, ils restent très performants pour un usage personnel (résumé, traductions, ..) . Néanmoins, soyez vigilants, les résultats des IA générative ne sont pas fiables et sont soumises aux hallucinations .
Les modèles d'IA Générative, appelés LLM, sont des modèles NLP (Natural Language Processing) de tailles élevés. Les modèles open sources ont une taille courante minimale de 4 à 6 Go (Mistral 7b, Gemma 9b, Llama 3.1 7b,...) et peuvent rapidement atteindre 40 Go. Ces modèles étant chargés en mémoire, il faut donc disposer d'un système avec suffisamment de RAM. Un bon GPU et CPU sont également indispensable pour disposer d'une bonne expérience utilisateur. Plus la taille du modèle est importante, plus la qualité de ses réponses sera élevée, mais plus les temps de réponses seront dégradés sur votre machine. Il y a donc un équilibre à trouver en fonction de votre équipement.
Dans cet article, nous installerons d'abord ollama qui est un outil facilitant le téléchargement, l'installation et la gestion de modèles LLM. Cet outil n'étant pas ergonomique, nous l'associerons à une IHM web openwebui. Cette interface ressemble aux interfaces classique pour dialoguer avec un assistant tel que celle de chatgpt ou celle de chat mistral ai. Elle est très facile d'emploi et vous permet de naviguer et d'utiliser aisément les modèles que vous avez récupéré ou mis à jour avec ollama.
Ce tutorial a été réalisé avec une machine PC comportant 32 Gb de RAM et une carte nvidia 3060 sous Mageia 9. Les drivers propriétaires de la carte nvidia ont été installés ainsi que l'extension opencl.
--Pré-Requis sur une environnement nvidia--
Code BASH :
urpmi python3-pip nvidia-current-cuda-opencl docker docker-compose
systemctl enable docker.service
systemctl start docker.service--Installation d'ollama--
Code BASH :
curl https://ollama.ai/install.sh | sh systemctl enable ollama.service systemctl start ollama.service
Installation de modèle localement
On décrit ici comment simplement télécharger et déployer un modèle LLM sur votre machine.
Téléchargement du modèle gemma2 9B - 9 milliards de paramètres- 5.5GB
Code BASH :
ollama pull gemma2
Téléchargement du modèle Mistral 7B - 7 milliards de paramètres 4.1GB
Code BASH :
ollama pull mistral
Téléchargement du modèle llama3.1 8B - 8 milliards de paramètres 4.7GB
Code BASH :
ollama pull llama3.1
Pour d'autres modèles voir le catalogue https://ollama.com/library
--Installation de openwebui pour interagir avec le modèle--
Openwebui sera déployé et installé avec l'image docker proposé par l'équipe projet.
Code BASH :
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- -v open-webui:/app/backend/data : Cela monte un volume nommé open-webui dans le répertoire /app/backend/data du conteneur.
- -d : Cette option signifie “détaché” et permet d’exécuter le conteneur en arrière-plan.
- --name open-webui : Cela attribue le nom “open-webui” au conteneur.
- --restart always : Cette option spécifie que le conteneur doit toujours redémarrer automatiquement en cas d’échec.
- ghcr.io/open-webui/open-webui:main : C’est l’image à partir de laquelle le conteneur sera créé
- --network=host Indicateur permettant de résoudre les soucis de connexion entre le conteneur et le service ollama qui expose le modèle.
- OLLAMA_BASE_URL=http://127.0.0.1:11434 , url de communication avec le service ollama, peut être configuré au niveau de l'ihm openwebui
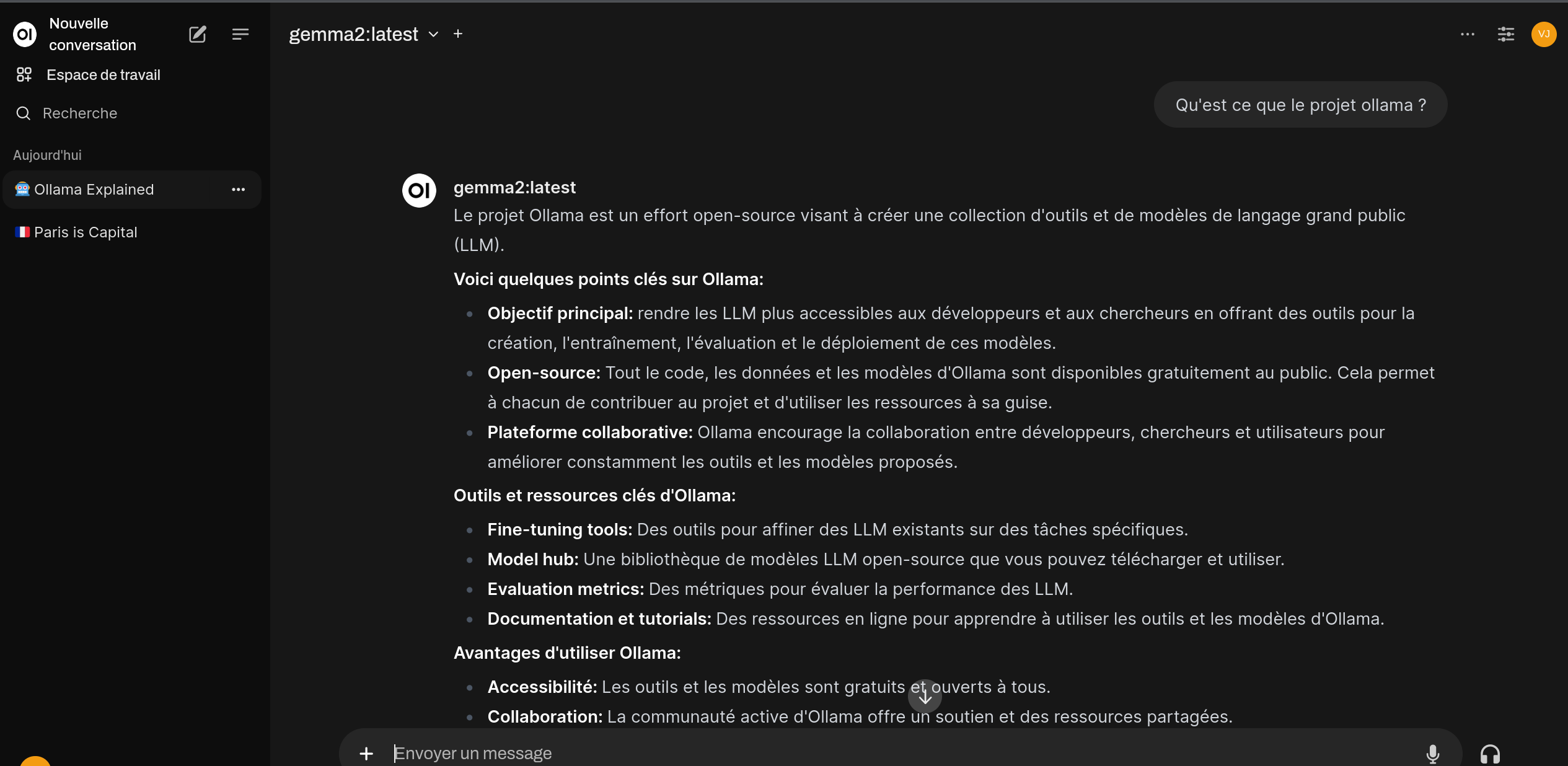
Se connecter ensuite à l'ihm à l'adresse http://localhost:8080
La création d'un compte est à réaliser une première fois.
On peut paramétrer le modèle utilisé soit au niveau de la partie administration pour tout les utilisateurs, soit au niveau du prompt.
Rappel des principales commandes docker
https://docs.docker.com/get-started/docker_cheatsheet.pdf
Rédigé par le vouf le 06/09/2024