Introduction
L'utilisation de modèles d'intelligence artificielle générative open source est en effet une option accessible pour de nombreuses applications personnelles telles que la rédaction de résumés ou la traduction de textes. Bien que ces modèles ne soient pas aussi avancés que ceux développés par des organisations comme OpenAI ou Anthropic, ils offrent néanmoins une performance remarquable pour les utilisateurs individuels. Il est important de noter que, malgré leur utilité, ces modèles peuvent parfois générer des informations incorrectes ou des hallucinations, où l'IA produit des données qui ne sont pas ancrées dans la réalité. C'est pourquoi il est crucial de toujours vérifier et critiquer les résultats fournis par ces IA, surtout lorsqu'ils sont utilisés dans des contextes où la précision est essentielle.
Les modèles de traitement du langage naturel, ou NLP, sont effectivement des outils puissants dans le domaine de l'IA générative. La taille des modèles open source varie généralement entre 4 et 40 Go, ce qui nécessite des systèmes informatiques avec une grande quantité de RAM pour les charger efficacement en mémoire. En plus de la RAM, un processeur (CPU) et une unité de traitement graphique (GPU) performants sont cruciaux pour optimiser l'expérience utilisateur. Il est vrai que plus un modèle est grand, plus il peut fournir des réponses précises et détaillées. Cependant, cela peut également entraîner une augmentation du temps de réponse. Trouver le bon équilibre entre la taille du modèle et les capacités de votre équipement est essentiel pour tirer le meilleur parti de ces technologies avancées.
L'installation d'outils comme ollama peut grandement simplifier le processus de gestion des modèles LLM (Large Language Models), en automatisant le téléchargement, l'installation et les mises à jour. Cependant, l'ergonomie n'étant pas toujours au rendez-vous, l'intégration d'une interface utilisateur web, telle que oopenwebui peut améliorer l'expérience utilisateur. Ces interfaces web offrent une ressemblance avec celles utilisées pour interagir avec des assistants virtuels, rendant ainsi l'utilisation des modèles LLM plus intuitive. Avec une interface bien conçue, les utilisateurs peuvent facilement naviguer entre les différents modèles, les utiliser, les mettre à jour ou les personnaliser selon leurs besoins spécifiques. Cela démocratise l'accès aux technologies de pointe en intelligence artificielle, permettant à un plus grand nombre de personnes de tirer parti de ces outils puissants pour diverses applications.
Ce tutorial a été réalisé avec une machine PC comportant 32 Gb de RAM et une carte Nvidia RTX 3060 sous Mageia 9. Les drivers propriétaires de la carte nvidia ont été installés ainsi que l'extension opencl.
Pré-Requis sur une environnement nvidia
Le driver propriétaire nvidia doit être installé préalablement. CUDA, même s'il n'est pas obligatoire, permettra d'obtenir des temps de réponses bien meilleures.
Code BASH :
urpmi nvidia-current-cuda-opencl
Pour vérifier le bon fonctionnement de votre solution, lancer la commande nvidia-smi depuis une konsole root
Code BASH :
[root@raptor ~]# nvidia-smi Sat Sep 7 10:15:44 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.100 Driver Version: 550.100 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3060 Off | 00000000:01:00.0 On | N/A | | 0% 48C P8 19W / 170W | 666MiB / 12288MiB | 3% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 1296 G /usr/libexec/Xorg 305MiB | | 0 N/A N/A 3883 G /usr/bin/kwalletd5 2MiB | | 0 N/A N/A 4131 G /usr/bin/ksmserver 2MiB | | 0 N/A N/A 4133 G /usr/bin/kded5 2MiB | | 0 N/A N/A 4135 G /usr/bin/kwin_x11 78MiB | |..... |......... |...... +-----------------------------------------------------------------------------------------+
Pré-Requis sur une environnement amd
Même si l'installation de rocm n'est pas obligatoire, il est conseillé sur un environnement disposant de cartes graphiques récentes pour tirer pleinement de la puissance de votre GPU et améliorer considérablement les temps de réponse.
Code BASH :
rocm-amd-opencl
Installation de docker et de pip
Code BASH :
urpmi python3-pip docker docker-compose
systemctl enable docker.service
systemctl start docker.serviceInstallation d'ollama
Code BASH :
curl https://ollama.ai/install.sh | sh
Puis démarrer le service en se connectant root
Code BASH :
systemctl enable ollama.service
systemctl start ollama.serviceInstallation de modèle localement
On décrit ici comment simplement télécharger et déployer un modèle LLM sur votre machine. Attention, par principe, le chargement du modèle va s'opérer principalement au niveau de la mémoire de votre GPU et/ou de votre mémoire RAM. Il faut veiller à ne pas prendre des modèles qui auraient une taille démesuré au regard de la RAM/DRAM dont vous disposer.
Téléchargement du modèle gemma2 9B - 9 milliards de paramètres- 5.5GB
Code BASH :
ollama pull gemma2
Téléchargement du modèle Mistral 7B - 7 milliards de paramètres 4.1GB
Code BASH :
ollama pull mistral
Téléchargement du modèle llama3.1 8B - 8 milliards de paramètres 4.7GB
Code BASH :
ollama pull llama3.1
Pour d'autres modèles voir le catalogue https://ollama.com/library
Configuration adaptée à docker du firewall shorewall
Editer le fichier /etc/shorewall/interfaces et ajouter la ligne suivante :
Code TEXT :
dock docker0
Editer le fichier /etc/shorewall/zones et ajouter la ligne suivante :
Code TEXT :
dock ipv4
Editer le fichier /etc/shorewall/policy et ajouter les lignes pour avoir :
Code TEXT :
do# fw net ACCEPT net all DROP info #Ajout Vouf dock fw REJECT dock all ACCEPT fw dock ACCEPT #Fin ajout all all REJECT info
Editer le fichier /etc/shorewall/shorewall.conf et modifier la variable DOCKER=No à
Code TEXT :
DOCKER=yes
Puis redémarrer shorewall
Code BASH :
systemctl restart shorewall.service
Installation de openwebui pour interagir avec le modèle
Openwebui sera déployé et installé avec l'image docker proposé par l'équipe projet.
Code BASH :
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- -v open-webui:/app/backend/data : Cela monte un volume nommé open-webui dans le répertoire /app/backend/data du conteneur.
- -d : Cette option signifie “détaché” et permet d’exécuter le conteneur en arrière-plan.
- --name open-webui : Cela attribue le nom “open-webui” au conteneur.
- --restart always : Cette option spécifie que le conteneur doit toujours redémarrer automatiquement en cas d’échec.
- ghcr.io/open-webui/open-webui:main : C’est l’image à partir de laquelle le conteneur sera créé
- --network=host Indicateur permettant de résoudre les soucis de connexion entre le conteneur et le service ollama qui expose le modèle.
- OLLAMA_BASE_URL=http://127.0.0.1:11434 , url de communication avec le service ollama, peut être configuré au niveau de l'ihm openwebui
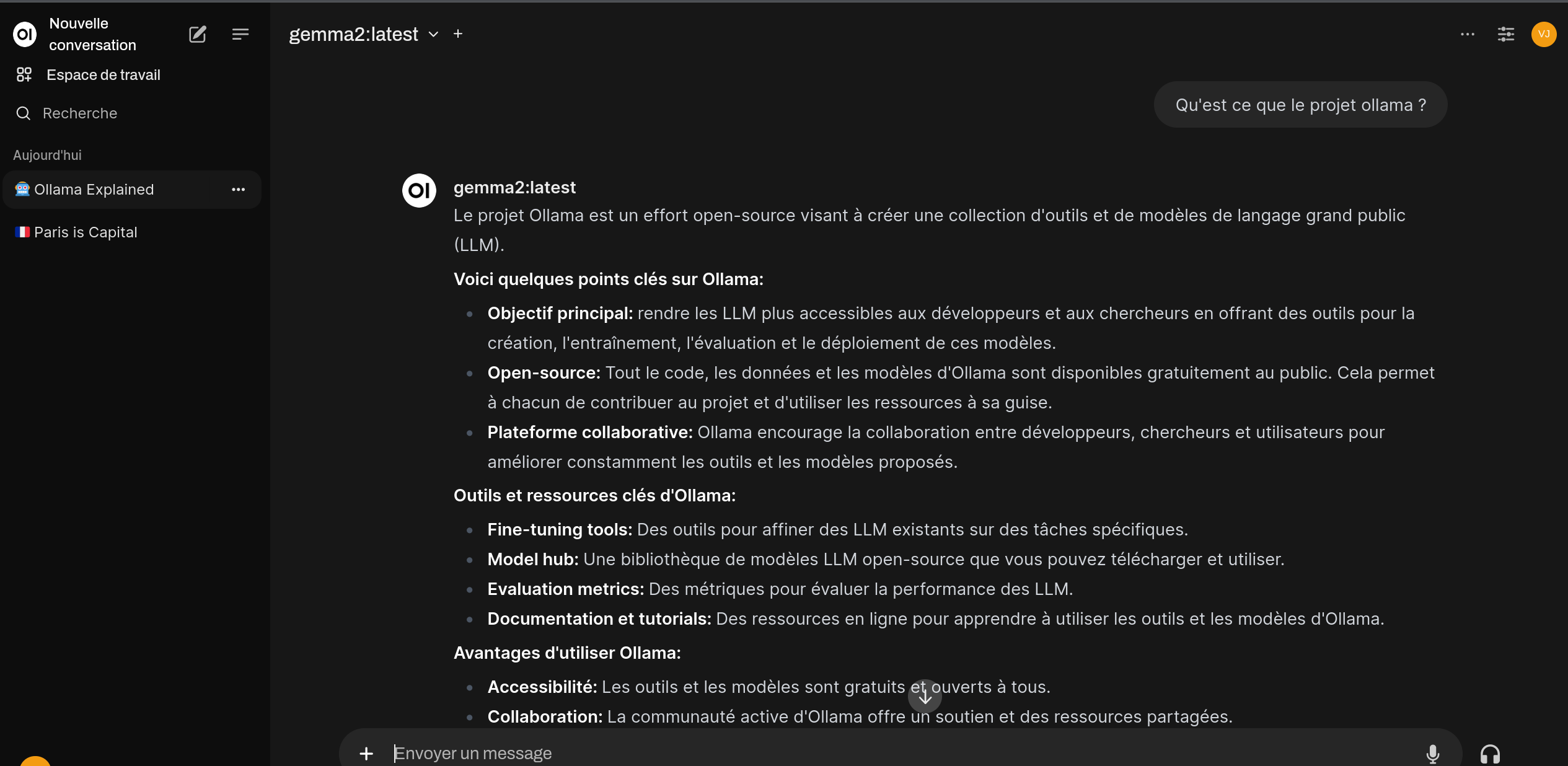
Se connecter ensuite à l'ihm à l'adresse http://localhost:8080
La création d'un compte est à réaliser une première fois. Renseignez un email et un mot de passe. Ce compte est uniquement sur votre machine.
On peut ensuite paramétrer le modèle utilisé soit au niveau de la partie administration pour tout les utilisateurs, soit au niveau du prompt.
Annexes
Rappel des principales commandes docker
Annuaire communautaire de référence des modèles open source
Rédigé par le vouf le 06/09/2024